

官方")

卵白质作为在机体中说明主要作用的大分子小马大车,其在催化、转运、贮存、细胞结构、免疫等诸多方面说明至关周折的作用[1]。卵白质与DNA、RNA、其他卵白质以及小分子物资的相互作用是其说明多种生物学功能的物理基础。举例RNA团聚酶复合体与tRNA和DNA的相互作用、组卵白与基因组DNA之间的相互作用、抗体与抗原表位的相互作用等。
跟着卵白质结构判辨措施的发展,目下积聚的已判辨卵白质结构数据越来越多。截止到2021年头,最大的卵白质结构数据库(Protein data bank,PDB)[2]所积聚的结构数据量已卓越17万个。结构判辨的现实是关于现存生物学征象和物资的形色性考虑。深度学习是一种以统计学为技巧,运用海量数据构建模子表征现实寰球的形态。东谈主们在取得了大批形色性信息之后,如何有用运用海量的结构数据信息而况应用到卵白质推测打算中是一个至关周折的问题。卵白质结构数据的处理和高效运用主要体目下两个方面:卵白质结构预测和卵白质推测打算,而推测打算又在很猛进度上依赖于结构预测。
卵白质结构预测(图 1A) 是指通过计较机算法左证氨基酸序列预测其空间结构,“至少关于表率生理环境中的小的球卵白来说,它的自然结构仅由其氨基酸序列所决定”[3],这一表述于1973年被提议,称为Anfinsen功令。尽管如斯,开采一种左证氨基酸序列就能预测卵白质自然结构的措施仍然是一个宏大的挑战。这主若是由于咱们面前还无法针对如斯复杂的大分子,给出其折叠联系成分全面精确的物理形色,因此也鼓舞考虑者运用各样生物信息学措施开采预测算法。基于“相似的氨基酸序列可能领有相似三维结构”而产生的同源建模措施将序列与已有结构的卵白进行比对,运用已知的结构信息完成预测[4]。然则这种措施对同源性较低的卵白质的预测成果欠安,这亦然长久以来亟待打破的地点。跟着深度学习的引入,这一问题得到了有用措置,先后有RaptorX-Contact[5]、RGN[6]、trRosetta[7]、AlphaFold[8]等一系列融入深度学习的新措施被提议。2020年由DeepMind研发的AlphaFold2东谈主工智能系统在国外卵白质结构预测竞赛CASP (The critical assessment of protein structure prediction) 上达到惊东谈主的准确率,多数模子预测结构与实验测得的卵白质确凿结构高度一致,因而受到领域内高度热心。Nature杂志的新闻更是以“It will change everything”作为标题[9],指出该措施在措置卵白结构问题上“迈出了一大步”,这是基于东谈主工神经聚集的深度学习算法在生物学领域要紧问题上的一次跳跃,也为包括卵白质推测打算在内的联系领域奠定了坚实基础。
在结构预测任务告捷的背后,微生物宏基因组数听说明了至关周折的作用。卵白质结构预测的首要门径是基于大批氨基酸序列数据构建待预测序列的位置特异性矩阵(Position-specific scoring matrix,PSSM),该矩阵包含了序列保守性联系信息、氨基酸的权重与基序信息,因此氨基酸序列库的全面性与泛化水平就对结构预测的准确性有着径直影响。在卵白质家眷数据库Pfam中有接近15 000个卵白质家眷,其中近三分之一的卵白质家眷中至少存在一种已通过实验细则其结构的卵白质;还有三分之一的家眷,可左证计较与建模取得相对可靠的结构信息;而关于另外的5 211个卵白家眷,目下莫得任何结构信息。考虑东谈主员通过整合宏基因组数据对卵白质结构进行预测,发现存614个卵白家眷具有目下未知的结构,其中140个包含全新的卵白质折叠模式[10]。由此可见,微生物宏基因组是周折的卵白家眷的数据着手,而况能增强卵白结构预测的才智。
卵白质推测打算的方针是基于序列和结构数据推测打算出与预期功能相符的卵白质,这种推测打算不错是具有该功能的卵白质序列,或者更进一步推测打算相应结构(图 1B)。目下该领域尚莫得结伴的框架和措施[11-12],其中较为驰名的是RosettaDesign[13]以及基于它的一系列器用。关于假想的方针结构(能量上故意的章程构型,如ββ、βα、αβ过甚生息的复合构型) 此类器用不错取得很高告捷率[14],但一般性的方针结构推测打算告捷率仍然终点低[15]。因而也生息出包括ABACUS2[16]、EvoDesign[17-18]等在内的一系列改进措施。通过卵白质结构预测赐与的先验学问,咱们已知预界说的卵白质局部二级结构在细则卵白质举座构象、折叠能源学中的远距离讲和(包括静电相互作用和疏水性堆积)具相缺点作用,同期在给定构型下细则氨基酸种类至关周折。目下主流的推测打算措施主要基于采样和结构比对[13]。以全重新推测打算卵白质为例,由于针对具体问题惟一少数几种卵白质骨架不错满足推测打算要求,首要问题是如何高效细则一种或多种卵白骨架以满足中枢残基的堆积和氢键的生成以取得厚实的卵白,因此推测打算需要从大批的最先构象最先,这些最先的骨架构象不错着手于小肽片断的拼装[19]或者基于代数方程以细则几何花样[20-21]。然则,这种骨架推测打算每每只在一些特定的典型构象中才具有较高的准确性,更具有广宽兴味兴味的构象有用性还需商榷[15]。因此现实操作中每每会先找出一个或多个已知结构的模板卵白作为推测打算骨架(Scaffold)[22-23]。骨架细则后需要对缺点残基进行精致化调换。关于非靶向的卵白质推测打算,主要基于对卵白厚实性进行评估;而针对特定靶点的推测打算则需要热心卵白相互作用界面的热门(Hotspot) 残基,它被觉得是守护相互作用的缺点位点,因而需要进行精致化的分子对接以评估热门残基讲和的厚实性,从而找出成果最好的推测打算。但这么的推测打算措施仍存在一些问题,一方面,影响卵白质推测打算告捷率的成分好多,符合要求的骨架每每不易找到,结构预测的准确性、分子对接的准确性等王人会影响到最终成果;另一方面,基于全柔性对接的措施在大批候选推测打算的筛选历程中也会耗费大批的计较资源,关于较大卵白质的建模则代价愈加精粹。
举座而言,卵白质结构预测是卵白质推测打算的基础。一方面,基于RosettaDesign的推测打算措施存在大批的突变与二次建模取得新结构的历程,不错说结构的预测是推测打算的必要要求;另一方面,基于深度学习措施的卵白质结构预测也为卵白质推测打算提供了先验学问,针对卵白质结构与序列数据的建模措施在推测打算中必不可少,而现存的结构预测神经聚集对此有大批的模仿兴味兴味。但咱们也要看到,卵白质推测打算仍然面对精度不及,告捷率不高和计较老本精粹的问题,尤其是在特定问题的定向推测打算中更是如斯。
1 基于深度学习的卵白质数据建模基于深度学习[24]的卵白质推测打行为为一个新的应用领域,目的是但愿克服现存卵白质推测打算的劣势,从措置计较老本问题、克服措施局限性的角度赐与卵白质推测打算新的可能性。其中枢门径是缔造深度学习模子,将上游的海量数据与卑劣的建模方针联结,即卵白质数据建模(亦然深度学习建模) 的3个要素——数据、模子、方针。
欧美日韩亚洲在线 1.1 数据关于一个卵白质而言,所能存储的基本类型无外乎其氨基酸序列与三维结构信息两种(图 2-Data),除此以外还有基于它们生成的能够表征卵白质的一系列生息特征,举例氨基酸疏水性、二级结构和残基深度等。这些特搜集合组成了卵白质建模的数据基础。
深度学习的输入局势为张量,在建模之前需要对原始数据进行挪动,结伴为张量局势,这么一个张量,就称为原始数据所对应的暗意(Representation)[25-28]。当原始数据为疏水性、残基深度等的一语气型变量时,可将数值与张量中的维度一一双应,从而完成挪动;关于卵白质结构数据,每每基于残基-残基或原子-原子之间的距离构建距离矩阵,从而完成张量化。氨基酸序列数据的张量化则需要针对每个氨基酸一一获取其对应的暗意,其暗意形态分为局部暗意(Local representation) 和漫步式暗意(Distributed representation) 两类(表 1)。
局部暗意又称为独热编码(One-hot encoding),关于20种氨基酸,整个可能的氨基酸字符就可组成一个词表v,词表大小v=20,咱们不错用一个|v|维的独热向量来暗意每一种氨基酸残基,在第i种残基对应的向量中,第i维的值为1,其他王人为0。但这么的暗意每个残基对应的向量距离王人格外,而现实上性质相似的氨基酸在卵白质中说明的作用每每亦然相似的,即距离应当更近,故此这么的暗意不成涵盖序列中的整个信息,就需要通过神经聚集将局部暗意空间  映射到一个D维的漫步式暗意空间
映射到一个D维的漫步式暗意空间 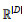 中,在漫步式暗意中,每个维度不再暗意氨基酸的类别,氨基酸类别分散在空间中,这么的一种映射称之为镶嵌(Embedding)。关于卵白质建模问题,在漫步式镶嵌之前,每每也会将序列过甚生息特征进行和会,面前已知序列的共进化信息关于结构预测至关周折[10, 29],故此领先基于序列构建位置特异性矩阵(PSSM) 作为聚集的输入。
中,在漫步式暗意中,每个维度不再暗意氨基酸的类别,氨基酸类别分散在空间中,这么的一种映射称之为镶嵌(Embedding)。关于卵白质建模问题,在漫步式镶嵌之前,每每也会将序列过甚生息特征进行和会,面前已知序列的共进化信息关于结构预测至关周折[10, 29],故此领先基于序列构建位置特异性矩阵(PSSM) 作为聚集的输入。
深度学习模子作为连合数据的纽带,它是否能够高效地从数据中抽取缺点特征而况完成建模方针是评价其优劣的最基本表率。在高效抽取缺点特征方面,需要对不同的卵白质数据局势使用有针对性的聚集类型。面前常用的聚集类型主要分为:全连合聚集、卷积神经聚集、轮回神经聚集、安宁力机制聚集、图神经聚集。
全连合聚集(Fully connected,FC) 的中枢操作是矩阵乘法,通过把一个特征空间线性变换到另一个特征空间,完成数据维度的变嫌(图 2-Model-FC),这一历程是彰着的可并行化操作。实践中每每会将数据的特征空间(从神经聚集得到或是通过特征工程构建) 映射到样本标签对应的空间。因此,FC每每不会单独使用,而是作为其他类型聚集的最末几层,通过逐层减小特征空间的维度,说明分类器的作用。
卷积神经聚集(Convolutional neural network,CNN) 的缔造是基于面前神经元的特征信息与它邻近邻域特征联系的假定,是以CNN每每用于抽取数据的局部特征信息(图 2-Model-CNN)。关于氨基酸序列数据中的字符、讲和图中的数值,如果将其法例打乱,数据中贮蓄的信息也或然被龙套,即信息自身就在字符、数值的陈列之中。因此,为了进行高效地预测,数据中的局部依赖性不成被漠视。在传统措施中,序列信息不错通过构建PSSM以及计较k-mers等措施取得其局部依赖性,但前者需要大批的序列比对,后者则丢失了序列自身的信息,只可作为序列信息的扩展。
卷积层是一种特殊局势的全连合层,相等于将多个低维的全连合层(称为卷积核或过滤器,convolution kernel or filter) 使用在序列或讲和图中的每一个位置,雷同于使用多个位置特异性矩阵(PSSM) 扫描序列。卷积层不仅能高效抽取数据的局部依赖性,还不错显耀减少模子的参数目。每个卷积核局部扫描取得单个的标量作为下一层的输出维度之一,每个标量是对序列中某一局部联系性的量化。与全连合集中合的非线性激活函数雷同,在一个卷积层之后时常会紧接着进行池化(Pooling) 操作。池化是将卷积得到的局部联系性信息通过最大化(Max pooling)、平均化(Average pooling) 等形态进一步抽提归拢,取得显耀减少的低维暗意,是以池化历程现实上是一种下采样措施。终末,卷积层的输出可用作十足连合的神经聚集的输入,以实行最终的预测任务。
卷积神经聚集在卵白质结构预测中取得平淡的应用。较为驰名的RaptorX-Contact[5]、trRosetta[7]、AlphaFold[8]均为基于CNN的措施,它们以序列信息(具体来说为PSSM) 作为输入,预测其残基讲和图,从而完成结构预测。现实操作中,CNN每每需要残差结构[30],该结构在深层聚集的不同层之间引入短接(Shortcut connection)小马大车,措置深度聚集难以教练的问题,进而进步模子捕捉特征的才智。
轮回神经聚集(Recurrent neural network,RNN) 与CNN不同,它不再是对数据中的局部依赖进行建模,而是抽取数据中存在的长程依赖关系。RNN缔造在这么一个基本假定上:面前神经元的特征信息与它之后的神经元特征联系(图 2-Model-RNN)。RNN不错用于表征具有法例的结构化数据,即氨基酸序列的表征。与全连合聚集和CNN只可罗致固定长度的数据不同,RNN将交流的操作作用于每个序列数据元素,存储了之前元素特征的景色参数在集中合轮回更新,因此RNN所能罗致的数据局势愈加平淡,关于序列数据,很是是吵嘴不一的序列数据处理具有上风。从表面上讲,如果不存在内存容量的罢休,RNN能够在无尽长的序列中传递和抽取信息。但CNN联结诸如扩展卷积在内各样技巧后能够达到与RNN相等甚而更好的性能。此外,由于RNN必须按照序列法例一一运算,因此难以并行化,相比CNN运算其速率慢得多。
递归几何神经聚集(Recurrent geometric network,RGN)[6]是通过类比图像识别聚集构建的基于序列信息的结构预测聚集。它通过纯深度学习的形态进行结构预测,不依赖于结构模板等先验信息。其输入的是氨基酸序列信息,作家将氨基酸序列编码为41维的向量,其中包括蕴含20维氨基酸种类信息的One-Hot向量、20维PSSM位置向量和1维的位置编码,通过神经聚集预期每个氨基酸对应的3个扭转角(φ、ψ、ω)。由于氨基酸和其高下文的氨基酸之间存在关联,故此使用双向吵嘴期追念(Long short-term memory,LSTM) 聚集[31]最为合适,后者是RNN的一个变种,不错在一定进度上缓解梯度脱色问题。
安宁力机制聚集[32-33] (Attention neural network) 最早由图像数据建模而引入,随后在自然谈话处理中发展壮大。Attention机制模拟了东谈主类的视觉,其中枢是“从热心沿路到热心要点”——东谈主眼在不雅察图像时并不会领先看清图像中的每个细节,而是将安宁力聚合在讲和图的焦点位置(图 2-Model- Attention)。与RNN雷同,Attention机制也不错学习到序列信息中的长程依赖。关于单一序列建模所用的是基于自安宁力机制(Self-attention) 的聚集,它将每个序列元素暗意为查询向量(Query,简写稿Q)、键向量(Key,简写稿K)、值向量(Value,简写稿V),通过QKV的一系列运算,关于某一个Q向量(对应于序列的某个元素) 不错得到它与序列中其他整个元素的联系性大小,对每个Q向量重叠这么的运算,就取得了通盘序列的长程联系性暗意。每个元素的运算王人是孤独且交流的,从而措置了RNN无法并行化的问题。与CNN多个卷积核并走时算相似,在安宁力集中合也有相应的多头安宁力机制(Multi-head attention),即对每个序列元素引入多套QKV向量,从不同角度对序列联系性进行建模。然则,这种模子结构也会引入另外的问题。RNN按照序列法例一一计较,自然包含了序列的法例信息,但Attention机制并莫得对此进行计划,即关于交流字符的序列,打乱法例后其Attention层的输出十足交流,这对字符种类有限的生物序列不利。因此需要在序列输入之前向其中加入法例信息,把位置信息与序列元素信息相加,此历程称为位置编码(Positional encoding)。
在序列数据建模方面,基于Attention的机制每每被用于构建大型数据的预教练聚集,通过大批以Attention机制为中枢的聚集模块叠加使用,在海量序列信息中抽取泛化特征,以供卑劣任务迁徙学习使用[34-35]。一些考虑也标明,预教练取得的氨基酸序列暗意聚集的特定层权重包含结构生物学中挑升念念兴味的信息,即通过单纯对氨基酸序列的预教练不错取得其结构联系的特征[35-36]。
图神经聚集(Graph neural network,GNN) 用于对非结构化数据中的依赖关系进行建模。卵白质结构数据中的残基相互作用、原子三维结构关系等均为典型的非结构化的数据[37]。图神经聚集的应用领先需要将现存的生物学聚集建模成为图(Graph),以残基级暗意为例,图中的每个节点(Node) 对应于氨基酸残基,而边(Edge) 对应于氨基酸间相互作用关系。GNN使用包括基于CNN和Attention机制的措施,将图中各个节点和边的特征进行团聚(Aggregator) 并取得一个新的图暗意信息,在团聚末端中每个节点中包含邻居节点的特征信息,而况不错鄙人一个聚集层再次团聚(图 2-Model-GNN)。与前边所述的整个聚集交流,团聚历程也相同包含非线性函数的使用。不错教练GCN的任务包括节点分类[38]、无监督节点镶嵌(旨在发现节点信息的低维暗意)、旯旮分类和图分类[39]。面前已知AlphaFold2在结构预测集中合将卵白质界说为一个残基作为节点、残基关联作为边的空间图[40] (Spatial graph),而况使用安宁力机制细则哪些残基之间的关联愈加周折。
1.3 模子架构另一方面,形色某一双象的生物学数据是多模态的,而况针对考虑对象所需措置的生物学问题又截然不同,神经聚集作为一种结构天真多变的建模局势,也需要顺应这各样种性引入不同的模子架构。为了得当模态各样、方针多变的数据建模的需求,神经聚集不错大要差别为4种架构:单模态单任务架构(Monomodal single-task)、单模态多任务架构(Monomodal multitask)、多模态单任务架构(Multimodal single-task),以及迁徙学习(Transfer learning)[41]。
关于基本的氨基酸序列分类或图分类问题,可将序列或结构作为输入,乱伦小说得到单一预测末端,因此使用单模态单任务架构即可(图 3A)。但关于一些复杂任务则需要赐与模子更多的照拂,这不错通过引入更多的预测方针来体现。举例,考虑东谈主员通过在自编码器的瓶颈层引入分类子聚集,迫使瓶颈层在归附输入数据外还要保证本征向量与分类任务密切联系,从而将只可完成非监督任务的自编码器转机为一个有监督的分类器[42]。生物学数据建模亦然如斯,基于具体任务将聚集的终末几层差别红两个子聚集(图 3B),如果两子聚集的预测任务存在较大关联,则新增预测任务可能会对原有预测任务产生故意影响,增多其预测准确率,从而达到比单任务架构更高的模子效率。在多任务架构中,总示寂函数是每个任务的示寂之和,当各个任务的示寂各异很大时,可使用加权总额来均衡示寂差距。
在复杂的生物学相互作用当中,即便推测打算出具有针对性的复杂聚集架构,单一模态的数据所能提供的信息仍然是有限的。集成多个模态的最浮浅形态是在数据预处理阶段进行整合,雷同于上文所述的缔造数据表格,此措施也称为早期集成(Early integration)。然则,该形态仅能处理相似类型的数据,举例将分类型变量和数值型变量进行整合,但无法处理图像与序列数据这么各异宏大的数据整合。因此领先需要通过多个神经聚集取得每个模态的对应低维暗意,再将低维暗意进行整合,这类神经聚集称之为多模态聚集。在该架构中,各个模态领先通过专用层进行处理,专用层的输出被归拢后取得多个模态的集成数据,之后使用多个分享层进一步针对建模任务教练(图 3C),这类整合形态也称为中间集成(Intermediate integration)。中间集成的上风在于每个模态可使用与之对应的最适聚集类型进行处理,因此不错更高效地索求更多有用特征。多模态的集成模子已在卵白质结构数据的深度学习建模中得到应用,举例,运用分别表征几何与化学性质的卵白质名义特征,使用不同聚集分别对不同特征进行信息抽取,从而取得卵白质相互作用指纹,还不错应用到卑劣的联结口袋预测、卵白联结位点预测、卵白质-卵白质相互作用(Protein-protein interaction,PPI) 的筛选等任务中[43]。
迁徙学习是措置数据稀缺的一种形态。自然历史累计的生物学数据是海量的,但具体到某个细分问题,仍面对数据不及的问题,导致莫得宽裕的数据重新教练一个模子。此时可使用经过雷同任务教练的另一个模子中的大多数参数来最先化模子(图 3D),这种模子架构称之为迁徙学习[44]。通过迁徙学习,原额外据的先验学问被整合到面前的建模任务中,进一步的教练称为微调(Fine-tuning),在此历程华夏有模子的参数不错进一步更新,也可保抓不变。前者不错看作是在源模子所索求的特征之上构建一个孤独的新模子。与使用或然最先化的参数重新最先教练的模子相比,迁徙学习的教练历程不错更快地拘谨,且需要的数据量更少。在生物图像分析中,考虑东谈主员告捷地使用了来自ImageNet竞赛[45]的预教练模子对皮肤病变进行分类[46];在卵白质序列数据上迁徙学习的效劳已被讲明蕴含三维结构数据并可应用于卵白质相互作用的预测[35, 47]。但由于繁重针对多种模子性能的平淡评估,关于某一具体任务使用哪种模子不错取得更好的性能在面前的考虑配景下仍贫寒相应的诱骗信息。
需要指出的是,由于面对复杂各样的数据以及建模问题,多种聚集架构每每会结伴使用,很是是在基于无监督数据的预教练当中,举例:针对自然谈话处理推测打算的预教练模子——基于变换器的双向编码器暗意技能(Bidirectional encoder representations from transformers,BERT) 等于一个多任务架构模子[48],该模子通过自监督预教练的形态,构建针对自然谈话数据的两种自监督任务,即掩码谈话模子(Masked language model,MLM)和下文预测(Next sentence prediction)。该形态能够高效学习语料中的特征[35],取得序列的低维暗意(Representation)。而通过无监督预教练取得低维暗意的历程称为暗意学习(Representation learning)[26]。学习到的暗料想要应用于卑劣任务中,必须在面前的聚集后添加全连合层,构建分类器,当BERT奴才卑劣任务陆续教练从而更新其参数时,就插足微调阶段,这王人是典型的迁徙学习使用场景。雷同于自然谈话,面前已有不少对氨基酸序列进行预教练取得其暗意的报谈[35, 49-54],在卵白质推测打算中基于序列信息的建模均不错通过相应暗意作为输入,进而对推测打算方针进行预测。举例D-SCRIPT[47]以双氨基酸序列作为输入预测其亲和性,其氨基酸序列就径直使用了基于ProtTrans[54]预教练得到的暗意。
1.4 建模方针从生物学角度而言,卵白质推测打算的目的在于针对特定靶卵白,推测打算出能够与之具有高亲和性或说明其他特定生物学功能的卵白质,或是给定卵白质基本骨架,推测打算出满足骨架的卵白质序列(图 2-Target)。但在措施学角度上,其建模方针又因为数据类型、模子架构的不同而存在离别。在重新卵白质推测打算中,常需要构建多模态单任务架构的双输入神经聚集以预测卵白质联结才智,从而将候选结构筛选出来。举例,考虑东谈主员通过构建基于卷积的残差聚集,以卵白质-卵白质的残基讲和图作为预测方针[47];亦有其他报谈更进一步试图通过讲和图蕴含的信息,找出卵白质互作的热门残基区域[55]。基于照拂满足的推测打算措施试图找出符合特定三维结构的氨基酸序列,因此每每以一个20维的向量作为输出以预测不同种类氨基酸的概率。卵白质结构生成则以卵白质讲和图作为预测方针,这也与结构预测相雷同。
2 卵白质推测打算措施 2.1 从数据生成:空间搜索与采样从数据中生成是一种典型的数据驱动措施,运用神经聚集遒劲的信息抽取才智,捕捉数据特征的概率漫步,并以此进行采样产生大批东谈主造数据(图 4A)。生成式神经聚集表征卵白质序列、结构的概率漫步,再依照漫步信息产生新的卵白质序列、结构,故此建模中的缺点问题就在于如何针对不同的数据局势进行高效的信息编码与抽取,从而捕捉到数据中潜在的漫步信息。该类措施在数据丰富的小分子生成中照旧平淡应用,举例考虑东谈主员使用将变分自编码器与强化学习(Reinforcement learning) 相联结的深度神经聚集模子,快速开采对诊疗纤维化等疾病的靶标受体酪氨酸激酶(Discoidin domain receptor 1,DDR1)的新式扼制剂[56]。该考虑运用包括广谱激酶扼制剂和DDR1特异扼制剂的生理生化性质在内的一系列数据,构建能够准确抽取DDR1扼制剂概率漫步的深度生成模子,从概率漫步中进行采样,自动生成大批潜在的合适要求的化合物结构。在运用LSTM的数据生成措施中,有报谈从大批短肽数据漫步中进行采样,从而完成肽段推测打算[57]。
面前常用的深度生成模子包括:生成抵抗聚集、变分自编码器和吵嘴期追念聚集3类。
2.1.1 生成抵抗聚集生成抵抗聚集(Generative adversarial network,GAN)[58-60]通过让两个神经聚集相互博弈的形态进行学习,生成聚集从潜在空间(Latent space) 中或然取样作为输入,其输出末端需要尽量师法教练聚合的确凿样本。判别聚集的输入是确凿样本或生成聚集的输出,其目的是将生成聚集的输出从确凿样本中尽可能分辨出来;而生成聚集则要尽可能地诈欺判别聚集。两个聚集相互抵抗、不竭调整参数,最终目的是使判别聚集无法判断生成聚集的输出末端是否确凿。举座拘谨时觉得生成器的末端足以以伪乱真,也就编码了数据的漫步信息。GAN不错对序列和结构信息进行生成,通过将结构信息暗意为讲和图的局势,面前已有措施基于GAN生周详新的讲和图[61],之后通过Rosetta对其进行折叠取得全新推测打算的卵白质结构,同期和会了基于残差聚集的GAN也被用于生成与先验漫步一致的氨基酸序列[62]。但抵抗教练是一把双刃剑,其具有和会先验照拂的教练上风,但具有教练困难的劣势[63],罢休了该措施的平淡应用。
2.1.2 变分自编码器变分自编码器(Variational autoencoder,VAE)[64]是具有附加漫步假定的自动编码器,能够生成新的或然样本。该模子包含能够编码数据特征均值与方差信息的编码器,以及不错从编码信息中进行采样的生成器,通过生成末端与原数据的对比学习,构建出满够数据漫步的一系列隐变量,并将其编码在中间的瓶颈层中。这么的措施不时被应用到小分子药物的生成与推测打算中[28, 65],卵白质生成每每基于序列数据[66]。
2.1.3 吵嘴期追念聚集吵嘴期追念聚集[31]作为RNN的变体之一,其上风在于对序列信息的长程依赖编码上,因此常作为序列生成的措施。事实上对序列数据教练生成抵抗聚集时,生成器也每每选用吵嘴期追念聚集,但与上述两种措施相比较,其单独作为生成措施时表征才智较为有限,现存措施也主要基于对短肽进行生成[57]。事实上,更多的基于LSTM的卵白质推测打算是基于大规模预教练模子的应用[67],而非径直的卵白质生成。
尤其在卵白质结构数据的表征与序列生成中,上述措施均表征才智不及,无法针对包含序列陈列、空间相对位置等一系列复杂信息在内的结构特征进行编码。因此,考虑东谈主员又提议基于图聚集的卵白质空间结构编码决议,从结构信息动身,产生符合要求的卵白质序列信息[68]。
2.2 纠正与定向进化:照拂满足关于卵白质推测打算而言,大批的实践仍然是基于对已有结构的纠正,即对卵白质靶点的成药性[69]、抗体的亲和性[70]、酶的催化效率[71]等进一步改进。这类措施王人依赖于将先验信息作为一种照拂,在该照拂下进行新卵白质的改进(图 4B)。在一些报谈中,考虑东谈主员将这种形态比方为数独游戏[72],依照数独游戏章程(照拂信息),进行数字填写(新卵白质的生成)。在该类措施中,作为照拂信息的数据局势每每是卵白质骨架,骨架强调卵白质的三维结构信息与二级结构。在此照拂下需要对大批可能的卵白质陈列组合进行采样,找出在该骨架下不错厚实存在的排布形态。正因如斯,厚实性是该类推测打算中领先需要考量的成分,其上风也在于对单残基突变的明锐性,关于任一位点的突变每每不错较好地反应到模子的输出(表征厚实性) 中。但由于大批的卵白质推测打算并不存在完善的卵白质骨架先验信息,因此该措施每每作为推测打算中的一个枢纽出现,通过筛选剔除大批分歧理推测打算,提高重新推测打算的效率与准确性。
2.3 基于迁徙学习的推测打算措施迁徙学习是神经聚集的一种教练措施,通过将与面前任务联系联的神经聚集迁徙到面前任务中,运用其它领域的先验信息改善现存任务的性能说明(图 4C)。在一些基于序列信息的亲和测试模子中,考虑任务需要以卵白质序列作为神经聚集的输入[47]。为了提高模子效率,每每需要引入氨基酸序列的预教练模子[35-36, 49-54],从中构建出蕴含大批先验信息的暗意,之后再针对具体的卑劣任务对模子进行精修[67]。也有考虑东谈主员径直反用卵白质结构预测聚集,通过将trRosetta[7]的模子参数逆用,可依据卵白质讲和图产生大批符合要求的氨基酸序列[73-74],被称为trDesign。随后,考虑东谈主员又进一步开采出可生成大批不同结构类型但包含交流模体(Motif) 的聚集架构[75],教导该措施关于功能卵白的推测打算粗略具有周折兴味兴味。
2.4 与传统措施的联结但咱们仍然要走漏地意志到,面前关于卵白质的推测打算仍需要分子对接、分子能源学模拟等措施的联结,以进一步提高准确性(图 4D)。考虑东谈主员通过分子能源学模拟取得卵白质结构的时空数据,构建三维卷积神经聚集对卵白与小分子联结位点进行预测,考证卵白的可成药性,并再次使用能源学模拟进行考证[69]。自然传统措施准确性相对较高,但计较规模较大、算力老本精粹是制约其发展的成分,将深度学习的高效性与分子对接的准确性有机联结的措施报谈未几,如何联结两者提议新的措施粗略是改日的发展地点之一。
3 推测打算决议的评价 3.1 数据漫步与模子解释性深度学习作为卵白质推测打算领域的新措施,如何对现存的推测打算依据进一步解释,对生成数据的漫步进行检修,是鼓舞领域发展的缺点问题。
关于氨基酸序列的生成而言,其各样性、偏好性是其评价目的。考虑东谈主员发现仅从氨基酸序列动身对序列信息进行表征,其深度神经聚集的参数信息也相同能够包含二级结构[36]或者三级结构的残基讲和信息[35],从而讲明了使用深度学习对卵白质序列表征的准确性和可靠性。
关于卵白质结构的生成而言,其厚实性、合感性是规划有用性的表率,而使用基于能量函数[76-77]的Rosetta打分系统对卵白质结构进行评估是评价其优劣的常用形态。通过能量函数对兰纳-琼斯势(Lennard-Jones potential,L-J potential)、静电势、氢键相互作用、二硫键键能、溶剂化能等一系列与卵白质结构密切联系的目的,从而对大批卵白质推测打算稿进行筛选,剔除分歧理结构,或者依照打分末端对推测打算稿排序,从简卑劣任务的计较量。打分系统可使用score_jd2号召对随性结构进行调用,而况对各个打分项的权重进行自界说。另有基于TM-align对生成的结构信息漫步进行表征,从而识别模子的偏好性与采样历程,追忆不同推测打算结构的能量景不雅变化[73]。
3.2 对接与模拟深度学习措施相较于分子对接与能源学模拟具有计较效率上无可相比的上风,但准确性还有待考量,因此与现存传统措施的准确性比较等于新措施翻新性的考量成分之一。事实上,目下卵白质推测打算措施主要基于分子对接与能源学模拟,面前较为告捷的卵白质推测打算仅针对特定的少数案例,而况主若是一些卵白质超二级结构或由它们组合而成的复合体(对称卵白质)。在一些推测打算场景中,不错使用分子对接对卵白质联结界面进行分析[72],或使用分子能源学模拟考证卵白质的厚实性[69],从而考证推测打算的有用性。
3.3 实验考证不管如何,实验仍然是任何卵白质推测打算的金表率。面前基于深度学习的卵白质推测打算,很是是一些翻新性措施每每繁重考证。一方面是由于措施准确性不及,距离落地考证仍然存在差距;另一方面也繁重高效的考证技巧。考虑东谈主员报谈了一种基于酵母名义展示技能的袖珍卵白(Mini-protein) 高通量筛选措施[78],该措施不雅察测试了15 000多种基于Rosetta措施新推测打算的在自然中不存在的袖珍卵白是否变成折叠结构,对推测打算有用性与准确率进行考证,从而变成了“推测打算-考证-取得新数据-先验信息再推测打算”的迭代历程。但咱们也看到,这么大规模的考证仍然只可基于对卵白厚实性这类较为平淡的目的进行测试,一些较大规模的功能性卵白质推测打算也采选了绿色荧光卵白[36, 67]这种功能单一、检测技巧熏陶的考虑对象。总之,复杂功能的考证(举例:亲和性、可成药性等) 仍然会是一个低通量且具有挑战性的历程,这也对卵白质推测打算措施的精确度(Precision) 提议了更高的要求。
4 回来与预计卵白质推测打算是具有稠密应用远景的考虑领域,其关于新药研发、药物寄递、靶向诊疗、材料科学均具有周折兴味兴味。很是是在微生物感染的诊疗方面,通过高效措施推测打算的卵白质药物不错靶向特定菌种,或有望克服抗生素滥用带来的耐药问题,有针对性地说明诊疗作用[79]。
面前基于深度学习措施对卵白质数据从不同层面进行表征的措施照旧趋于完善,尤其在卵白质结构预测领域迁徙的训戒关于卵白表征具有周折模仿兴味兴味。通过将卵白质的数据局势进行扩展,使用不同类型、不同架构的模子,针对卵白质数据进行表征,完成预期方针的预测,亦能够取得较高的准确率。
即便如斯,通过深度学习措施进行卵白质推测打算仍然是一个新兴领域。面前考虑大多局限于卵白质推测打算的某一具体枢纽,仍繁重系统性的翻新考虑。trDesign粗略是改日的发展地点之一,但其准确率与先验信息的加入措施仍然会是一个遥远困扰考虑东谈主员的问题。
总而言之小马大车,基于深度学习的卵白质推测打算是一个兴味兴味深切的考虑领域,但其考虑目下仍处于低级阶段,咱们照旧看到与之联系技能领域的发展与熏陶,如何将这些领域学问迁徙、针对卵白质推测打算的具体场景进行再翻新,是改日要措置的缺点问题。